Unlocking the Power of LLM Evaluation with Precision
As large language models (LLMs) become core tools for modern applications, evaluating their performance accurately and consistently is no longer optional—it's essential. Whether you're building AI assistants, chatbots, or any LLM-driven solution, understanding the quality of generated responses is key to improving user experience and ensuring reliability.
At Precision, we've made LLM evaluation a central pillar of the platform. Our goal is simple: help teams and developers measure, analyze, and optimize their AI-generated content with confidence.
Why LLM Evaluation Matters
Not all AI-generated responses are equal. Some are insightful and accurate. Others are vague, biased, or flat-out wrong. Human review is helpful—but not scalable. That’s where automated, intelligent evaluation steps in.
Precision offers an evaluation engine that doesn’t just score outputs—it thinks through them.
What Makes Precision’s Evaluation Unique?
Our evaluation process is designed to mimic human reasoning with depth and consistency, while offering more transparency than a simple thumbs-up/down rating.
Here’s how:
Self-Questioning & Justification:
The backend architecture guides high-performing LLMs to reflect on responses, question their own conclusions, and provide justification. This "think-before-you-score" method leads to more accurate grading.
Multiple Internal Passes:
Rather than relying on a single pass, Precision runs multiple evaluation cycles internally. This helps reduce bias, filter inconsistencies, and boost the reliability of final scores.
Detailed Feedback, Not Just a Number:
Every evaluation returns more than just a score out of 10. You get:
An explanation of what worked and what didn’t
Suggestions for improving the response
A color-coded analysis showing strong, weak, and neutral content at the word level
Visual Scoring Scale:
Each evaluated response is color-coded based on score:
🔴 0–4 (Red): Poor quality
🟡 5–8 (Yellow): Average quality
🟢 9–10 (Green): High quality
This gives users quick visual insight into performance without losing the details that matter.
Evaluation, Your Way
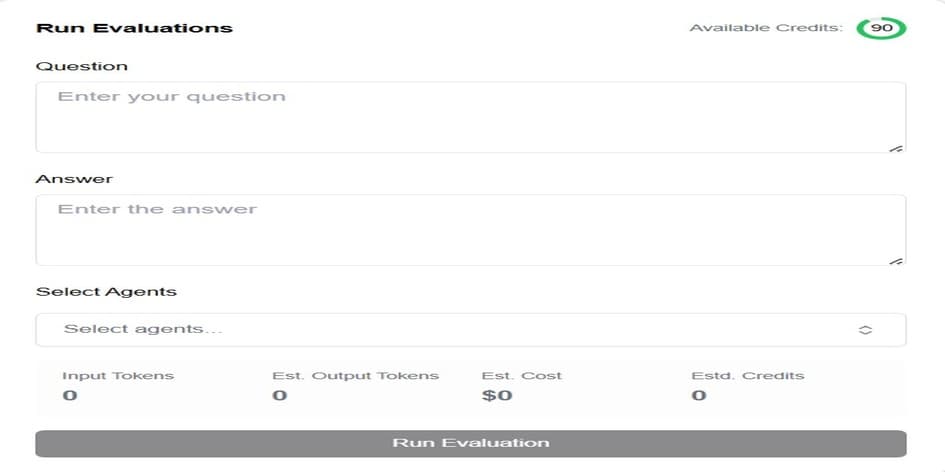
Whether you're testing a single prompt or analyzing thousands of responses, Precision makes evaluation accessible and adaptable. We currently offer three modes of evaluation:
Quick Evaluation for instant feedback
Dataset Bulk Evaluation for large-scale testing
API-Based Evaluation for seamless integration into custom pipelines
👉 Try Quick Evaluation now: https://precisionapp.ai/dashboard
(We’ll cover each of these in depth in upcoming posts.)
Built for Teams, Developers, and Builders
The Precision evaluation system fits into any stage of your LLM development process. Use it to:
Debug LLM outputs during early development
Benchmark models during fine-tuning
Monitor real-world performance after deployment
Teach teams how to write better prompts and understand model behavior
Final Thoughts
Evaluating LLMs should be as intelligent as the models themselves. With Precision, we're building tools that go beyond surface-level scoring—tools that help you truly understand and improve the outputs your users see.
Stay tuned for detailed posts on each evaluation type. And if you haven’t yet, try out a Quick Evaluation today and see the difference for yourself.